I recently completed a project measuring how well large language models (LLMs) can translate natural language queries into MongoDB queries.
The Benchmark
Over spring 2025, I developed a benchmark to evaluate how different LLMs perform at generating MongoDB Shell (mongosh) code from natural language queries. The benchmark consists of 766 test cases across 8 databases using the MongoDB Atlas sample datasets.
Here’s what I evaluated:
Models Evaluated
- Claude 3.7 Sonnet
- Claude 3.5 Haiku
- GPT-4o
- GPT-4o-mini
- o3-mini
- Gemini 2 Flash
- Llama 3.3 70b
- Mistral Large 2
- Amazon Nova Pro
These models represented the state-of-the-art from major AI labs at time of benchmarking.
Key Evaluation Metrics
- SuccessfulExecution: Does the generated query run without errors?
- CorrectOutputFuzzy: Does it return the right data?
- XMaNeR: The primary composite metric combining execution success, correctness, non-empty output, and reasonable results
Key Findings
Model Performance Correlates with General Capabilities
The results show a strong correlation (R² = 0.615) between how well models perform on this MongoDB benchmark and their performance on general benchmarks like MMLU-Pro. This suggests that as models get better overall, they’ll continue improving at MongoDB-specific tasks.

Top Performers
- Claude 3.7 Sonnet - 86.7% average XMaNeR score
- o3-mini - 82.9% average XMaNeR score
- Gemini 2 Flash - 82.9% average XMaNeR score

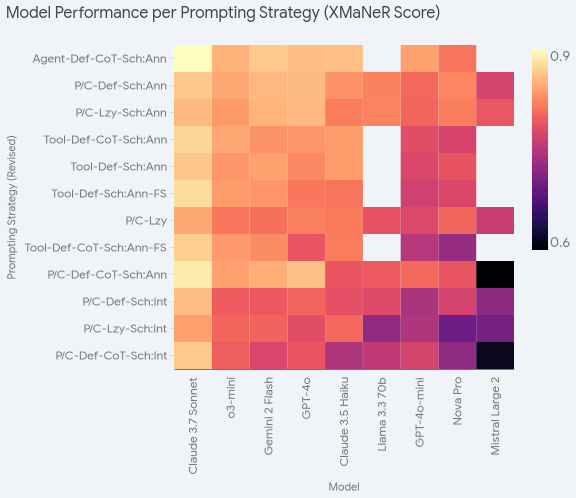
Prompting Strategy Matters (But Less for Better Models)
Different prompting approaches produced meaningfully different results. Interestingly, the highest-performing models were less sensitive to prompting variations - Claude 3.7 Sonnet had only a 5.86% range between best and worst experiments, while lower-performing models like Mistral Large 2 had an 18.72% range.

Most Effective Prompting Strategies
- Include annotated database schemas (significant positive impact)
- Always provide sample documents from collections
- Use agentic workflows for maximum performance (but at higher cost/latency)
- Avoid interpreted JSON schemas (can confuse models)
Practical Recommendations
Based on these benchmark results, here are actionable recommendations for building natural language to MongoDB query systems:
- Invest in annotated schemas - describing what database fields mean meaningfully improves results
- Always include sample documents in your prompts if possible. Models understand these better than programmatically generatedDB schemas.
- Test different prompting strategies for your specific model and use case
- Consider the cost-performance trade-off of agentic approaches
Dataset
Dataset Profile
The benchmark dataset consists of 766 test cases distributed across 8 MongoDB Atlas sample databases. The dataset includes diverse query complexities and MongoDB operations.


Dataset Generation Pipeline
Rather than manually creating the necessary hundreds of test cases, I built a scalable pipeline that programmatically generates natural language queries and their corresponding MongoDB queries.

The generation process follows this flow:
- User personas: Generate diverse user types who might query the database
- Use cases: Create realistic scenarios for each user persona
- Natural language queries: Generate multiple ways each user might ask their question
- MongoDB queries: Create the corresponding mongosh code to answer each question
- Filter: Only include queries where a plurality of LLMs agree on the correct answer and more than one LLM is able to answer correctly. This ensures that the query is ‘answerable’.
Advantages of This Approach
- Scalable: Generate
Nusers ×Muse cases ×Pnatural language queries ×OMongoDB queries. For example, 8×8×8×8 = 4,096 test cases. - Flexible: The process adapts to any MongoDB database. Simply point it at your collections.
- Extensible: Intervene at any step to create targeted datasets for specific features or use cases. For example, in the NL query generation step, you could prompt it to only create timeseries-related queries.
This approach creates a comprehensive benchmark that covers realistic query patterns while maintaining quality and relevance to actual MongoDB usage.
Resources and Documentation
Dataset and Detailed Results Analysis
The complete dataset, benchmark results, and source code are available on HuggingFace.
Source Code
The benchmark generation pipeline and evaluation code can be found in the MongoDB Chatbot repository.
MongoDB Documentation
Building on these benchmark findings, the MongoDB documentation team and I created new guidance for building natural language to MongoDB query systems. You can find the official documentation at Natural Language to MongoDB Queries. This page includes practical prompting strategies and best practices derived from this research.
The documentation covers optimal prompt components, example schemas, and implementation patterns that emerged from testing thousands of natural language to MongoDB query translations across different models and configurations.