
RAGE with the Machines
October 29th, 2023
RAGE stands for Retrieval Augmented Generation and Execution. It’s an architecture for building LLM-powered applications that can execute actions on the user’s behalf.
RAGE is useful because it lets you execute a functionally infinite number of actions from a LLM-powered application.
High-Level Flow
On a high level, this is how RAGE works:
-
Data ingestion: In a background job, ingest a set of actions for the RAGE app to access.
- You store a set of instructions for performing actions in addition to vector embedding representations of the actions. Index the vector embeddings with a vector search index.
-
Application: Executes the RAGE flow based on the ingested actions.
-
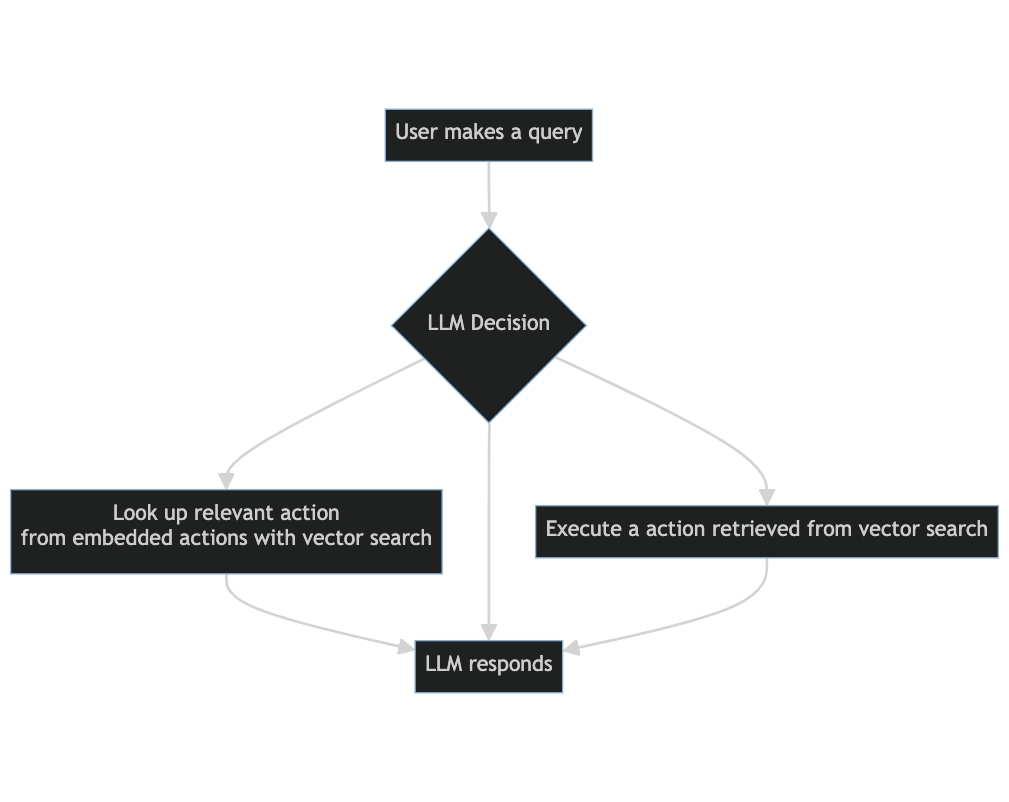
Application flow on each user query:
- User makes a query
-
LLM decides to do one of the following baked in actions:
- Look up relevant action from embedded actions to satisfy user request with vector search
- Execute a dynamically action on behalf of user (will not exist on first query, only after action has been added to the conversation)
- No additional action taken (proceed to next step)
- LLM answers user based on the user’s query and action information from previous step
-
Here's a diagram of what the RAGE application flow looks like:
Concrete Example
Here’s a concrete example of how you could use a RAGE application to plan a trip.
Data Ingestion
Store embeddings and instructions for variety of HTTP APIs (weather, shopping, plane tickets, etc.) in MongoDB Atlas using Atlas Vector Search.
Chat Flow
- User asks: I’m going to the south of france in october. what will the weather be like?
- LLM: based on user query, looks up action that can answer question. The lookup returns
GET /weatherHTTP API specification from a weather service - LLM: maps user query to a request to this API, and executes that request to the API. Returns results.
- LLM: summarizes results to user, “the weather will be 60 degrees Fahrenheit…”
- User: ok colder than i expected! i’ll need to buy a light jacket then. find me a blue one from uniqlo for under $50
- LLM: based on conversation, look up action to answer question. The lookup returns
GET /itemsfrom the Uniqlo API. -
LLM: asks user, what size are you? to perform the search i need to know
- (this is based on a required field in the
GET /itemsspec)
- (this is based on a required field in the
- User: large
- LLM: maps information to request to API, and executes the API. returns results.
- LLM: summarizes results to user, “uniqulo has 3 options…”
- ...conversation continues
PAGE to RAGE: From O(c) to O(n) Actions
To underscore the importance of RAGE’s ability to use a vector store to include executable actions in your application, let’s contrast it with the current standard for executing actions from a LLM conversation: Plugin Augmented Generation and Execution (PAGE). In PAGE, you bake in a finite set of actions to the prompt that the LLM can perform.
The most prominent example of PAGE is ChatGPT Plugins. The way ChatGPT plugins work is that before every conversation, you select which plugins you want to use in that conversation. Plugins are baked into the system prompt, and the LLM evaluates if they should be called every time you send a message. While plugins certainly provide utility, they are inherently limited by the fact that you need to know what plugins you want to use before the conversation begins.
A plugin based approach is inherently limited by the fact that you do not necessarily know which plugins you want to use at the start of the conversation. For example, in the above conversation example about travel planning, the user probably did not know that they wanted to include access to the Uniqlo product catalogue when the conversation started.
Also, having to decide which plugins you want to use at the start of the conversation can be a cognitive load on the user that could deter them from choosing to use plugins at all.
I suspect these reasons are a big part of why ChatGPT plugins haven’t proved very popular. (I recall seeing somewhere that they’re used in less than 1% of conversations, but can’t find a link. If you Google “chatgpt plugins reddit” you’ll see a lot of lukewarm-at-best feedback.)
To use computer science speak, PAGE lets you use O(c) plugins, where C is the finite number of actions baked into the system prompt.
Using the same Big-O logic, RAG is O(1) actions, where the single action is using content retrieval to inform the LLM result.
RAGE, in contrast, let’s you use O(n) actions, by storing all the available actions in the vector store, allowing you to bypass context-length limitations of including actions in a LLM application.
RAGE Can Be a Superset of RAG or PAGE
A RAGE application must have the following actions baked into it’s functionality:
- Find relevant actions
- Execute action
- Respond to user
You could also bake in additional actions that you want to always be present in the conversational context. For example, in a general purpose chatbot, you might want to always have web search baked in. For a domain-specific chatbot, you might want to have RAG question answering always present as an option.
This pushes the app to use these baked in actions with fewer calls, and guides the app to choose to use these specific actions (instead of searching a retrieving a potentially different one).
Limitations
I think the RAGE architecture offers a lot of promise for expanding the functionality of LLM-powered apps, but the following limitations still exist on it:
- Context window still matters. Even though you can include a functionally infinite amount of actions in a RAGE app, the app is still beholden to the LLM context window when interacting with the actions. This means that you might lose some context from earlier in the conversation outside the context window and you have to limit response size from actions.
- LLMs aren’t AGI (yet?). LLMs make mistakes, often ones that people would not.
- RAGE does not create autonomous agents. The RAGE architecture doesn’t include a framework for chaining together actions to execute arbitrary broad-scoped tasks.
There’s probably a lot more relevant limitations, but these are the ones that come to my mind right now.
A Practical Example: Chat with the MongoDB Atlas Admin API
During a recent hackathon a work, our team created a chatbot that uses RAGE to interact with the MongoDB Atlas Admin API. For example, you can ask it who the users are in your organization, or to create a cluster on your behalf.
Our source code is here: https://github.com/mongodb/chatbot/blob/api_chat/.
[MongoDB employees only]:
- You can see a demo here: https://www.youtube.com/watch?v=Td5mWXSOLVs.
- And use the demo site
Implementation Details
We based our implementation on the ChatGPT API using functions. Using ChatGPT functions is the most straightforward way to implement a RAGE app as of present (late October 2023), but theoretically other LLMs could do the same.
Here’s some code snippets from our implementation of the RAGE.
Our system prompt:
// systemPromptPersonality is where you can put in stuff specific to your chatbot
const baseSystemPrompt = `${systemPromptPersonality}
Use the find_api_spec_action function to find an action in the API spec when the user asks you to perform an action.
If none of the available functions match the user's query, use this function.
Before performing an action, ask the user for any missing **required** parameters.
Before performing a POST, DELETE, PUT, or PATCH function, ask the user to confirm that they want to perform the action.
`;The OpenAI functions we used:
export const baseOpenAiFunctionDefinitions: FunctionDefinition[] = [
{
name: "find_api_spec_action",
description: "Find an action in the API spec",
parameters: {
type: "object",
properties: {
query: {
type: "string",
description:
"Repeat the user's query to perform a search for the relevant action",
},
},
required: ["query"],
},
},
// this could be generalized more or customized to your chatbot
// to allow for different execution types
{
name: "make_curl_request",
description: `Make a curl request to an endpoint based on the available relevant information in the conversation
ALWAYS USE HTTP digest authentication.
Check the system prompt for relevant additional information, like \`groupId\` and \`clusterName\`.
Keep the "--user {username}:{password}", the system will fill it in later.
Example curl request:
curl --user "{username}:{password}" \
--digest \
--header "Accept: application/vnd.atlas.2023-02-01+json" \
-X GET "https://cloud.mongodb.com/api/atlas/v2/groups/{groupId}/dbAccessHistory/clusters/{clusterName}"`,
parameters: {
type: "object",
properties: {
curl_request: {
type: "string",
description: `The curl request to make to the API endpoint.`,
},
},
required: ["curl_request"],
},
},
];How we execute the functions:
// Notice that in addition to the response message from the LLM,
// we also pass staticHttpRequestArgs and credentials.
// These are variables to use in the API request that the LLM does not have access to.
// (Like you definitely shouldn't pass an API key to the LLM.)
async function handleOpenAiFunctionCall({
responseMessage,
newMessages,
findContent,
credentials,
staticHttpRequestArgs,
}: {
responseMessage: ChatMessage;
newMessages: OpenAiChatMessage[];
findContent: FindContentFunc;
credentials: HttpApiCredentials;
staticHttpRequestArgs?: HttpRequestArgs;
}) {
assert(
responseMessage.functionCall,
"No function call returned from OpenAI. This function should only be called if it's validated that the response message has the `functionCall` property."
);
const { name } = responseMessage.functionCall;
// The LLM has chosen to find action(s) in the API spec.
// We add the action(s) to the set of available functions.
if (name === "find_api_spec_action") {
const { query } = JSON.parse(responseMessage.functionCall.arguments);
// Call function to find relevant action(s) in the API spec
// and add them to the set of available actions
const { content: apiSpecActions } = await findContent({
query,
ipAddress: "FOO",
});
newMessages.push(responseMessage as OpenAiChatMessage, {
role: "function",
name: "find_api_spec_action",
content: makeFunctionMetadataContent(apiSpecActions[0]),
});
} else if (name === "make_curl_request") {
const { curl_request } = JSON.parse(responseMessage.functionCall.arguments);
const response = await executeCurlRequest(
curl_request,
credentials,
staticHttpRequestArgs
);
newMessages.push(responseMessage as OpenAiChatMessage, {
role: "function",
name: "make_curl_request",
content: `The API responded with:\n\n` + response,
});
}
return newMessages;
}
// our logic for executing the cURL request
export async function executeCurlRequest(
curlCommand: string,
credentials: HttpApiCredentials,
staticHttpRequestArgs?: HttpRequestArgs
): Promise<string> {
const originalCurlCommand = curlCommand;
curlCommand = curlCommand.replace("{username}", credentials.username);
curlCommand = curlCommand.replace("{password}", credentials.password);
// Replace path params
for (const pathParametersKey in staticHttpRequestArgs?.pathParameters) {
curlCommand = curlCommand.replace(
`{${pathParametersKey}}`,
staticHttpRequestArgs.pathParameters[pathParametersKey] as string
);
}
for (const queryParametersKey in staticHttpRequestArgs?.queryParameters) {
const url = new URL(curlCommand);
url.searchParams.append(
queryParametersKey,
staticHttpRequestArgs.queryParameters[queryParametersKey] as string
);
curlCommand = url.toString();
}
return new Promise((resolve, _reject) => {
exec(curlCommand, (error, stdout, stderr) => {
console.log({ error, stdout, stderr });
if (stdout) {
logger.info("stdout::", stdout);
if (stdout.length > 3000) {
resolve(
"The message was too long to fit in the LLM context window, but here's the beginning of it:\n" +
stdout.slice(0, 3000)
);
return;
}
resolve(stdout);
return;
}
if (error !== null) {
logger.error(error);
resolve(`There was an error executing the curl command:
${originalCurlCommand}`);
return;
}
if (stderr) {
logger.error(error);
resolve(`There was an error executing the curl command:
${originalCurlCommand}`);
return;
}
});
});
}To ingest the relevant actions to the API, we used our existing chatbot ingest pipeline with a custom data source for pulling in an API specification. Here’s the implementation of that: https://github.com/mongodb/chatbot/blob/api_chat/ingest-atlas-admin-api/src/config.ts. The code is a little long to include here. (again it’s currently closed source, but just ask me, and i’ll give you access to view it).
Conclusion: RAGE on!
I think the RAGE architecture has a lot of promise for expanding the scope of what LLM-powered apps can do. RAGE leverages two of the great powers of LLMs: serving as a reasoning engine and natural language summarization.
And RAGE solves for some of the main limitations of LLMs: the limited context window and lack of interface to connect to external systems.
I’m looking forward to exploring the RAGE paradigm more and building out the tools you need to operationalize it in real world contexts.